
AI search on private data using Langchain and Elasticsearch
Code but not data for this experiment can be found here: github
This is likely just the first of a series of weekend projects where I’ll dip my toe into the deep waters of AI and vector embeddings. ChatGPT is eye-opening but has one major problem. It’s a closed-hosted system. After twenty years of living in a world transformed by large web companies, we as people fear our private information or even our knowledge to become the property of others just because we use the Internet. As participants in an economy built on competition, we have a healthy distrust of the centralization of knowledge and data in the hands of companies with histories of anti-competitive practices.
So the question at hand is this: can I get a local Large Language Model with generative AI chat working on my laptop using no cloud services? I’m not an expert in AI, it’s not something I’ve ever studied, but after spending a week on Youtube learning about vector embeddings and prompt templates I’m ready to put my hands to the keyboard.
What I’m going to build
In short: I’m going to build an AI chatbot that ‘knows’ things that are not in its pre-trained neural network by combining an LLM with a vector store.
I’m going to start with a frequently tutorialed project best described as “Talk to my Books.” I didn’t invent this, a quick search finds some other approaches usually using paid OpenAI APIs. example, video example
I’ll start with the very first bit of private data I used to search on. The Lord of the Rings. I had a DRM free version of the Lord of the Rings novels back before the online bookstores got their act together. Converting it to a simple .txt file and using Notepad search made a Tolkien research paper infinitely easier back when I took a student-directed class on Tolkien literary criticism. Given how many physical and digital copies of this book I have purchased, I consider this well within fair use.
This data is perfect because Tolkien does not write in clear declarative sentences like in a research paper or self-help book. This is not Wikipedia. Information is not organized in an entity-oriented fashion and is not prepared for question answering. This is hard mode and my results will likely suffer, but hopefully, it will make a better environment for learning.
How this will work
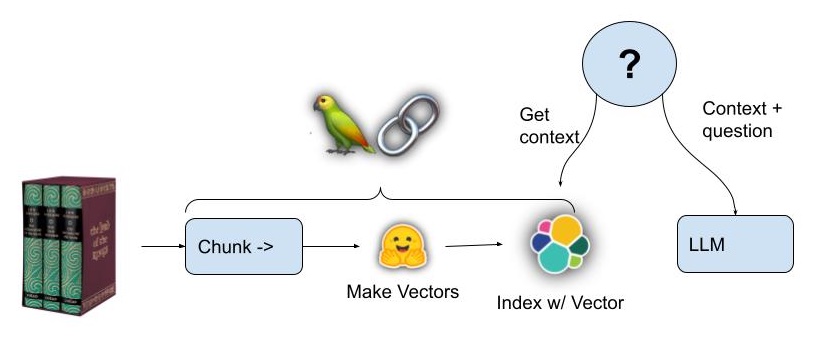
The key steps:
- Text is extracted into small paragraph-sized chunks, enough to hold the answer to a Tolkien trivia question.
- Each chunk of text is handed to a sentence transformer, which generates a dense vector to represent its semantic meaning as a vector embedding
- The chunks are stored in Elasticsearch with their vector embeddings
- When a question is asked, a vector is created for the question text and then Elasticsearch is queried to find the chunk of text which is semantically closest to the question; presumably some text that will have the answer.
- A prompt is composed for a LLM that “stuffs” the retrieved text chunk in as extra contextual knowledge.
- The LLM Creates an answer to the question
Langchain keeps this simple
There is a great python library called Langchain which not only includes utility libraries to make working with transformers and vector stores simple, and somewhat interchangeable. Langchain has more advanced patterns of working with LLMs than I’ll use here, but this is a good first test.
Many of the Langchain tutorials out there require using a paid OpenAI account. OpenAI is great, and may be leading the LLM quality race right now, but for all the reasons stated above I’m going to use free HuggingFace models and Elasticsearch.
Getting some offline models
One must create an account in Huggingface and get an API key. After that, you can programmatically pull down models using huggingface_hub python libraries or Langchain.
For no other reason than I was able to get them working offline without a GPU on my intel MacBook I’ll be using
- sentence-transformers/all-mpnet-base-v2 - as my vector embeddings generator
- google/flan-t5-large - as my Large Language Model for conversational interaction
Setting it up
Creating the embeddings model
from langchain.embeddings import HuggingFaceEmbeddings
def setup_embeddings():
# Huggingface embedding setup
print(">> Prep. Huggingface embedding setup")
model_name = "sentence-transformers/all-mpnet-base-v2"
return HuggingFaceEmbeddings(model_name=model_name)
Creating the vector store
import os
from langchain.vectorstores import ElasticVectorSearch
def setup_vectordb(hf,index_name):
# Elasticsearch URL setup
print(">> Prep. Elasticsearch config setup")
endpoint = os.getenv('ES_SERVER', 'ERROR')
username = os.getenv('ES_USERNAME', 'ERROR')
password = os.getenv('ES_PASSWORD', 'ERROR')
url = f"https://{username}:{password}@{endpoint}:443"
return ElasticVectorSearch(embedding=hf, elasticsearch_url=url, index_name=index_name), url
Creating the offline LLM that has uses a prompt template with both context and question variables
from langchain import PromptTemplate, HuggingFaceHub, LLMChain
from langchain.llms import HuggingFacePipeline
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, AutoModelForSeq2SeqLM
def make_the_llm():
# Get Offline flan-t5-large ready to go, in CPU mode
print(">> Prep. Get Offline flan-t5-large ready to go, in CPU mode")
model_id = 'google/flan-t5-large'
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(model_id) device_map='auto'
pipe = pipeline(
"text2text-generation",
model=model,
tokenizer=tokenizer,
max_length=100
)
local_llm = HuggingFacePipeline(pipeline=pipe)
template_informed = """
I know: {context}
when asked: {question}
my response is: """
prompt_informed = PromptTemplate(template=template_informed, input_variables=["context", "question"])
return LLMChain(prompt=prompt_informed, llm=local_llm)
Loading the books
The following is my chunking and vector store code. It requires having an Elasticsearch url composed, huggingface embeddings model, vector db, and target index_name in Elasticsearch ready to go
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import TextLoader
from elasticsearch import Elasticsearch
def parse_book(filepath):
loader = TextLoader(filepath)
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
return docs
def loadBookBig(filepath, url, hf, db, index_name):
with Elasticsearch([url], verify_certs=True) as es:
## Parse the book if necessary
if not es.indices.exists(index=index_name):
print(f'\tThe index: {index_name} does not exist')
print(">> 1. Chunk up the Source document")
docs = parse_book(filepath)
print(">> 2. Index the chunks into Elasticsearch")
db.from_texts(docs, embedding=hf, elasticsearch_url=url, index_name=index_name)
else:
print("\tLooks like the book is already loaded, let's move on")
Tie it all together with a question loop
With the book parsed the main control loop goes like this
## how to ask a question
def ask_a_question(question):
# print("The Question at hand: "+question)
## 3. get the relevant chunk from Elasticsearch for a question
# print(">> 3. get the relevant chunk from Elasticsearch for a question")
similar_docs = db.similarity_search(question)
print(f'The most relevant passage: \n\t{similar_docs[0].page_content}')
## 4. Ask Local LLM context informed prompt
# print(">> 4. Asking The Book ... and its response is: ")
informed_context= similar_docs[0].page_content
response = llm_chain_informed.run(context=informed_context,question=question)
return response
# The conversational loop
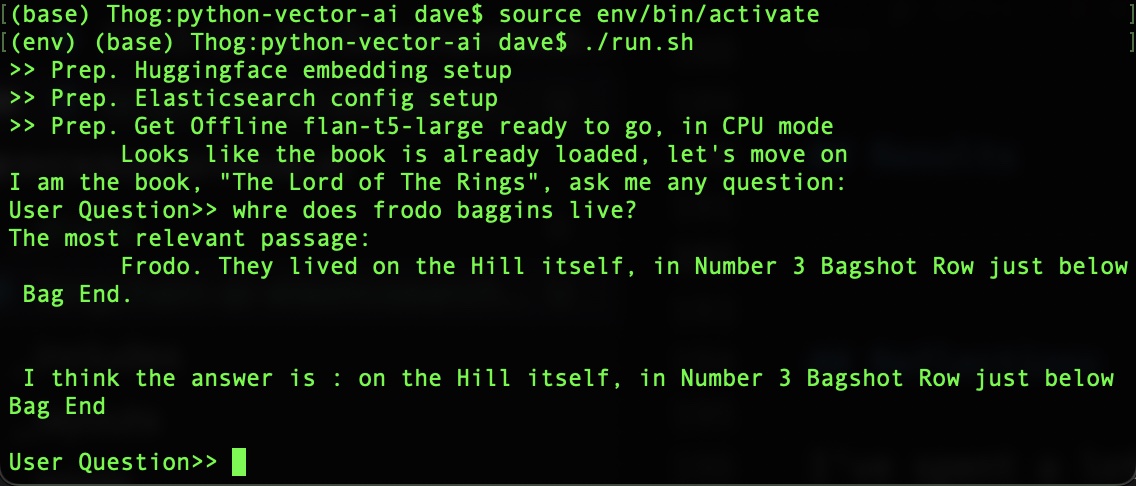
print(f'I am the book, "{bookName}", ask me any question: ')
while True:
command = input("User Question>> ")
response = ask_a_question(command)
print(f"\n\n I think the answer is : {response}\n")
Results
Reflections
I have mixed thoughts about Langchain. If I was better at python and knew instinctively how to extend the Langchain code to do exactly what i wanted it is exactly the kind of Quality of Life library that we all want to work with. At this point though, I’m tempted to do more of this by hand both to fine-tune my queries, get multiple chunks of knowledge from Elasticsearch, and maybe play around with the embeddings models being hosted in Elastisearch itself, which is the newer method: (tutorial here)
Raw knowledge from a novel is hard, and I picked a hard one. Next time I’m going to try a data set that is more question-and-answer oriented or even a Wikipedia-like entity-oriented page of text.
This experiment has proven to me that private data AI search is very possible. In this quickly maturing space, I’m interested to see if I can get it working to a high quality in a self-hosted and even air-gapped environment.