
Label-based Access Control in Elasticsearch
Update: Elasticsearch added many of the tools needed (and mentioned in the Further Work section below) to implement very clean ABAC policies in Elasticsearch 6.1. This method below is out of date
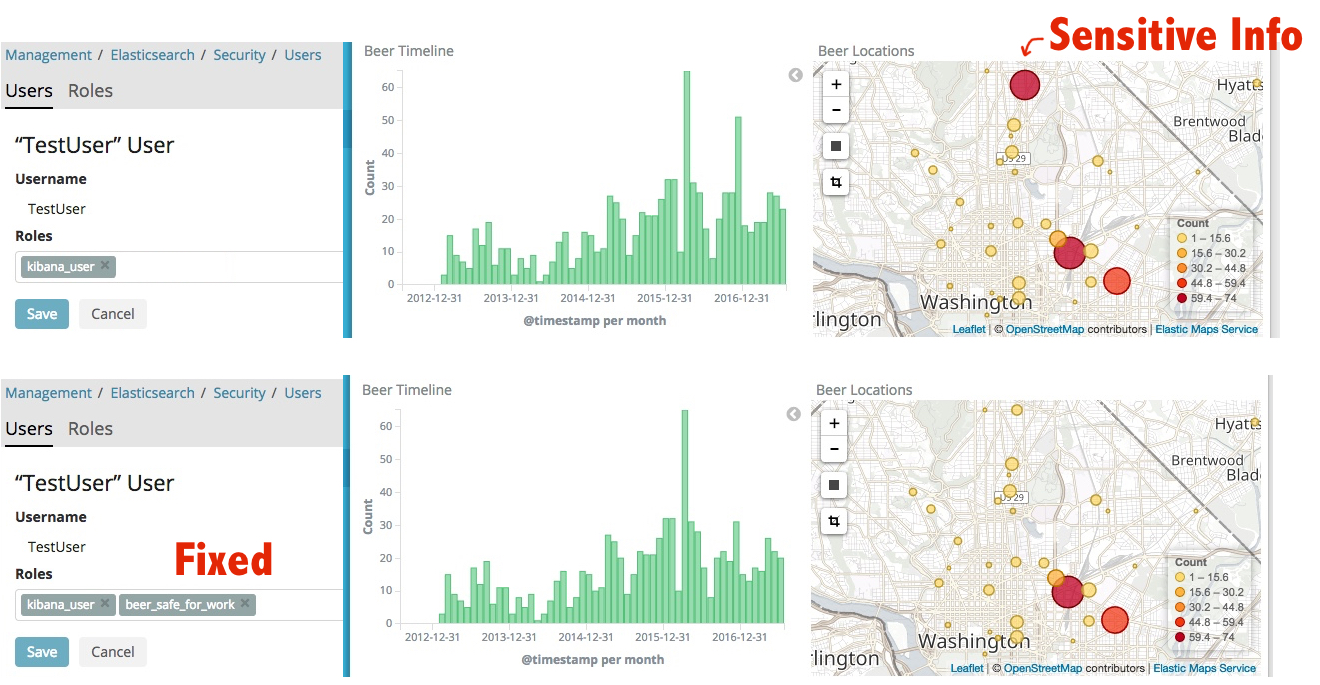
Securing Sensitive Data
RBAC is great, but doesn’t fit the security policies I deal with at work. HIPAA, Financial Services portfolio management, and multi-tenanted SaaS products all generate data that is sensitive enough to deserve Mandatory Access Controls (MAC) at the data layer and basic access control policies often don’t cut it. This isn’t just a problem at work though …
The tech we wear, bolt to the walls of our homes, and even just walk by on the street generates a large amount of personalized infromation about our lives. I aggregate a good amount of that in my Quantified Self project and have been showing my Untappd beer dashboard around now for a few years as a fun basic example of logging personal data in Elasticsearch and visualizing that data with Kibana. It’s fun and makes for a good demo! However, one of the big challenges people face once all this data is aggregated is that it is now that much more publicly visible than when it was a csv file sitting on my private hard drive. Not only can someone presumably glance around and learn things about me that I didn’t want them to (my favorite bars, that I’m not a fan of IPAs) but they can learn things that I consider sensitive such as my exact home address. Even worse are the potential for misinterpretations. In my beer dashboard when I check-in a flight of small-sized taster beers, it looks like I’ve had 4 whole pints of beer.
Throwing off my analytics with it's deliciousness (Freemont Brewing Company in Seattle, WA)
Okay, I’m not so worried about flights of beer, but let’s use this as a test data set for creating a fine grained access control policy in Elasticsearch that will enforce data protection in any analytic app or UI, including unmodified Kibana. Rather that working to create a complex Document-level security query that secures data (remember the RDBMS stored procedures that secured data and how difficult to maintain they were) let’s take a Label-based approach with my beer data as a way of explaining the how and why this approach is so important to some users of data systems like Elasticsearch.
Label-based vs. Document-level RBAC
Document-Level Role Based Access Control (RBAC) can be expressed with a simple forward query in X-Pack Security (Example, Documentation)
This is fine, but is error prone and hard to maintain or modify if you aren’t a developer. The number of RDBMS data silos that exist in this world for no reason other than no one still employed at the company knows how to modify the PL/SQL that secures the data is shameful.
Label-based controls (LBAC) are a specific implementation of Mandatory Access Control (MAC) that takes the principle of least privilege (no label –> no access) and allows security policies that reqire a user to have an AND (union) and possilbly and AND of OR’s. A basic example
Imagine I have a document with sensitive health information for a patient. To access that data, a user must be on the medical team that cares for that specific patient AND someone on the team that has a need to see personal health information. Just one of these being true isn’t enough. A user needs both to be able to search, retrieve, and aggregate this data in our use case.
POST /health_sensors/temp/1
{
"@timestamp": "2017-08-02T00:00:12Z",
"patientId": "123456789",
"bodyTempF": 98.5,
"tags": ["patientId_123456789", "EPHI"]
}
In an LBAC model, I now can grant the “patientId_123456789” and “EPHI” roles to a users and this information should be accessible. Having a role-per-label in RBAC won’t work because roles are implicitly OR’d and any single role will give access to the document. Equally policies my have other restrictions or dimension in some cases. If you want a complex example, check out all the complex different dimentions of CAPCO markings which can be simplied down to
SECURITY_LEVEL//COMPARTMENT1/COMPARTMENT2//REL TO Country1, Country2
or logically
To access this document, the user must satisfy:
user.security_level >= SECURITY_LEVEL
AND
user.security_compartments must contain both
COMPARTMENT1 AND COMPARTMENT2
AND
user.nationality must be either Country1 OR Country2
Notice this is a logical conjuction (aka a big AND) of smaller AND, OR, and scalar comparison statments.
Annotating Beer With Percolator
To secure my beer data I’ll want to annotate each document with labels that manufacture some categories for the sensitivity of the data. I’d define 3 tags.
- Beer - this is a ganeric label that will exist on all beer checkins. Every beer will have it. Without access to the BEER lablel, Elasticsearch will not admit that I’ve ever checked in a beer.
- DomesticBeer – all beers manufactured in the United States. A good test label to validate that LBAC filtering is working as it will show up plainly in all my dashboards.
- HomeDrinking – Beers checkedin near my home address.
I’ll now define three pecolation queries and reload my beer data tagging the data model with security lavels. The full source code for my python data loader is here, but the key percolation queries look like this:
allBeerMatcher = {
SECURITY_TAGS_FIELD: "Beer",
PERCOLATE_FIELD: {
"match_all": {}
}
}
domesticMatcher = {
SECURITY_TAGS_FIELD: "DomesticBeer",
PERCOLATE_FIELD : {
"match": {
"brewery_country": "United States"
}
}
}
homeLocation = [LON, LAT] ## the thing I am trying to protect
homeMatcher = {
SECURITY_TAGS_FIELD: "HomeDrinking",
PERCOLATE_FIELD : {
"geo_distance": {
"distance": "100m",
"location": homeLocation
}
}
}
When the data is ingested, it looks like this
{
"beer_ibu": 10,
"serving_type": "",
"venue_name": "Colony Club",
"beer_name": "Oberon Ale",
"beer_url": "https://untappd.com/beer/16581",
"flavor_profiles": "",
"venue_state": "D.C.",
"securityTags": [
"Beer",
"DomesticBeer"
],
"venue_city": "Washington",
"brewery_state": "MI",
"created_at": "2016-08-11 20:10:18",
"beer_abv": 5.8,
"brewery_name": "Bell's Brewery",
"rating_score": "",
"comment": "",
"@timestamp": "2016-08-11T20:10:18",
"venue_lat": "38.9296",
"venue_country": "United States",
"checkin_url": "https://untappd.com/c/347180969",
"purchase_venue": "",
"beer_type": "Pale Wheat Ale - American",
"brewery_city": "Galesburg",
"location": [
-77.0236,
38.9296
],
"brewery_url": "https://untappd.com/brewery/2507",
"securityTag_Count": 2,
"brewery_country": "United States",
"venue_lng": "-77.0236"
}
The Missing Array Match Query
The next step is to build a simple test query. If a user has rights to “Beer” and “DomesticBeer” but not “HomeDrinking” then the query needs to check that the user’s labels provide full coverage of the required tags per-document. Unfortunately no such query operator exists in Elasticsearch’s query DSL, so we’ll have to create it with some extra data modeling and combinatorial logic. I call this the combinatorial array match query.
Inside the data we encoded an extra piece of information, the length of the security tag array:
"securityTag_Count": 2
this allows us to write the basic logical expression
(Beer AND securityTag_Count == 1) OR (DomesticBeer AND securityTag_Count == 1) OR (Beer AND DomesticBeer securityTag_Count == 2)
If the user had all three tags the logic would look like this:
(Beer AND securityTag_Count == 1)
OR
(DomesticBeer AND
securityTag_Count == 1)
OR
(HomeDrinking AND
securityTag_Count == 1)
OR
(Beer AND
DomesticBeer AND
securityTag_Count == 2)
OR
(Beer AND
HomeDrinking AND
securityTag_Count == 2)
OR
(DomesticBeer AND
HomeDrinking AND
securityTag_Count == 2)
OR
(Beer AND
DomesticBeer AND
HomeDrinking AND
securityTag_Count == 3)
Our lives would be easier if there was some syntactic sugar (and later in-server optimization) for an array coverage query, but we can do the above logic with Elasticsearch’s bool query
{‘bool’: {‘should’: [[{‘bool’: {‘must’: [[{‘term’: {‘securityTags’: ‘Beer’}}, {‘term’: {‘securityTag_Count’: 1}}]]}}, {‘bool’: {‘must’: [[{‘term’: {‘securityTags’: ‘DomesticBeer’}}, {‘term’: {‘securityTag_Count’: 1}}]]}}, {‘bool’: {‘must’: [[{‘term’: {‘securityTags’: ‘HomeDrinking’}}, {‘term’: {‘securityTag_Count’: 1}}]]}}, {‘bool’: {‘must’: [[{‘term’: {‘securityTags’: ‘Beer’}}, {‘term’: {‘securityTags’: ‘DomesticBeer’}}, {‘term’: {‘securityTag_Count’: 2}}]]}}, {‘bool’: {‘must’: [[{‘term’: {‘securityTags’: ‘Beer’}}, {‘term’: {‘securityTags’: ‘HomeDrinking’}}, {‘term’: {‘securityTag_Count’: 2}}]]}}, {‘bool’: {‘must’: [[{‘term’: {‘securityTags’: ‘DomesticBeer’}}, {‘term’: {‘securityTags’: ‘HomeDrinking’}}, {‘term’: {‘securityTag_Count’: 2}}]]}}, {‘bool’: {‘must’: [[{‘term’: {‘securityTags’: ‘Beer’}}, {‘term’: {‘securityTags’: ‘DomesticBeer’}}, {‘term’: {‘securityTags’: ‘HomeDrinking’}}, {‘term’: {‘securityTag_Count’: 3}}]]}}]]}}
or with nice json indenting: pretty json version
Here is the recursive python code for quickly creating the combinatorial set query: code link
Creating a Per-Person X-Pack Security Role
For the person with these roles we then create a role that represents the combo of the two document. Technically you only need to create a role for each unique combination of tags that exists in your user base. People implementing this in production generally create a per-user role or per-distinct combination role when the user logs in after checking the central authority story for user rights.
POST /_xpack/security/role/beer_safe_for_work
{
"cluster": [],
"indices": [
{
"names": [
"beer"
],
"privileges": [
"read"
],
"query": {
"bool": {
"should": [
[
{
"bool": {
"must": [
[
{
"term": {
"securityTags": "Beer"
}
},
{
"term": {
"securityTag_Count": 1
}
}
]
]
}
},
{
"bool": {
"must": [
[
{
"term": {
"securityTags": "DomesticBeer"
}
},
{
"term": {
"securityTag_Count": 1
}
}
]
]
}
},
{
"bool": {
"must": [
[
{
"term": {
"securityTags": "Beer"
}
},
{
"term": {
"securityTags": "DomesticBeer"
}
},
{
"term": {
"securityTag_Count": 2
}
}
]
]
}
}
]
]
}
}
}
],
"run_as": [],
"metadata": {},
"transient_metadata": {
"enabled": true
}
}
Future Work and Reading
To make this as easy as possible for implementers I’d love to see the combinatorial set code built into Elasticsearch itself so that we can use the role query templating function to generate all roles dynamically from a single templated role. (That will make the CAPCO example a lot easier)
My queries could probably use some tuning work to make sure filter caches are kicking in (there aren’t as many distinct combinations of user rights as the possbible combinatorial explosion) and I’m not wasting time scoring documents etc.
Clever people reading this may have realized it’s faster to check for ‘must_not’ have HomeDriking than it is to check for all the combiantions of the other tags. A good discussion of use-case by use-case optimization of LDAP using knowledge of the tags, tag cardnality etc can be found here: Discuss conversation from 2016
My general hope is that LBAC can help people implement better security controls in Elasticsearch. It’s important to keep private data under control in an easy to maintain fashion and I’m going to continue working on this example in the future to make operationalizing LBAC easier and easier for implementers.